深度学习:Xavier and Kaiming Initialization

目前deep learning存在这样几种模型初始化策略:
- Constant Initialization;
- Random Initialization;
- Xavier Initialization;
- Kaiming Initialization;
下面简单介绍Constant Initialization和Random Initialization,重点推导Xavier和Kaiming初始化。
1. Constant Initialization
将神经网络中的模型全部初始化为某个常数,意味着将所有计算单元初始化为完全相同的状态,这会使每个计算单元对同一样例的输出和反向更新的梯度存在某种对称关系或甚至完全相同,导致神经网络的灵活性大打折扣。
2. Random Initialization
Random Initialization将每个计算单元初始化成不同的状态,但却无法很好选择概率模型中的超参数,例如正态分布 中的 和 ,均匀分布 中的 和 。Xavier Initialization和Kaiming Initialization正是为了解决这个问题而提出的。
3. Xavier Initialization
Xavier Initialization和Kaiming Initialization的motivation是使信号强度(使用Variance度量)在神经网络训练的过程中保持不变。
下面以FC节点为例来说明,Conv计算同理。
1.1 Forward
其中, 、 、 和 为随机变量(Random Variable,简称r.v.),且 , , 。
要满足前向计算信号强度不变,就需要满足: 。
引入假设:
- 、 、 are independent of each other;
- i.i.d. and (i.i.d.,独立同分布,independent and identically distributed,这里表示每个神经元之间相互独立,每个神经元内部的模型也相互独立。)
- i.i.d. and ;
- i.i.d. and ;
假设1说明输入数据和模型无相关性;假设2、3和4说明输入数据内部和模型内部的数据无相关性,且均值为0(个人认为后面3个假设过强,可能与实际情况不符);
其中, 是输入向量的维度。若要实现 ,则必须满足 ,即: ,进一步得出初始化方式:
- 若 服从正态分布,则 ;
- 若 服从均匀分布,则 ;
1.2 Backward
其中, 、 和 是r.v., , , 。
若要做到后向计算信号强度不变,就需要满足: 。
引入假设:
- and are independent of each other;
- i.i.d. and ;
- i.i.d. and ;
同样,个人认为假设2和3过强了,可能与现实不符。
其中, 是FC这一层的神经元个数,也就是FC前向输出的维度。若要满足 ,必须保证 ,即 ,进一步得出初始化方式:
- 若 服从正态分布,则 ;
- 若 服从均匀分布,则 ;
1.3 取调和平均数
根据上面的推导可以看出,除非 ,否则我们无法同时保证前后向信号的Variance不发生变化,所以原论文中对 取了一个调和平均数: ,进一步得到模型初始化方式:
- 若 服从正态分布,则 ;
- 若 服从均匀分布,则 ;
4. Kaiming Initialization
Xavier初始化假设网络中没有激活函数,而激活函数会改变神经网络中流动数据的分布,Kaiming Initialization正是为了解决这个问题而提出的。
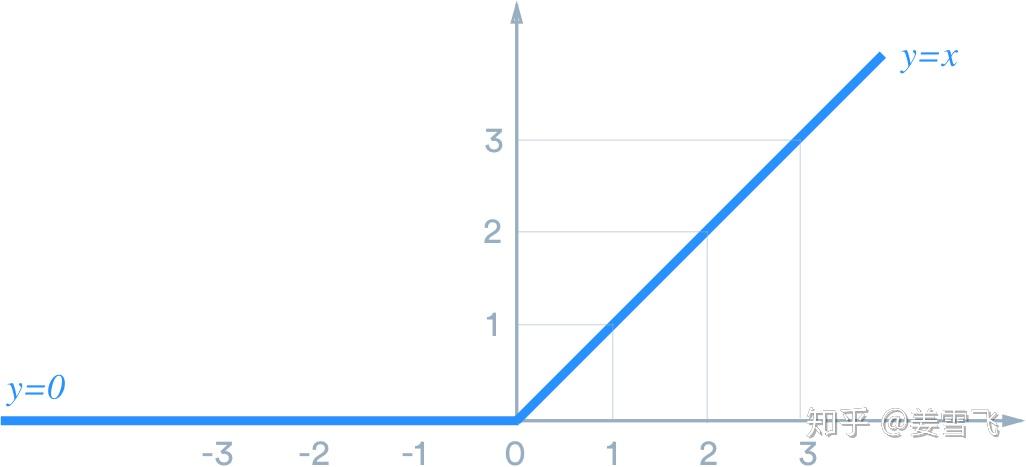
下面以FC + ReLU这个组合为例推导下Kaiming Initialization。ReLU激活函数如下图所示:
1.1 Forward
其中, 、 、 、 和 为r.v., 为ReLU激活函数,且 , , 。
在Xavier Initialization的基础上引入一条新假设:
- has a symmetric distribution around zero;
若要做到前向计算信号强度不变,就需要满足: , 根据上面新加的假设有: ,然后沿着Xaiver的逻辑推导得出:
- 若 服从正态分布,则 ;
- 若 服从均匀分布,则 ;
2.2 Backward
同理可推导Backward,需要指出的是FC前向的推导使用的是FC前面的激活函数,后向的推导应该使用FC后面的激活函数,这里也假设是ReLU,这里直接写出结论:
- 若 服从正态分布,则 ;
- 若 服从均匀分布,则 ;
2.3 其他激活函数
其他激活函数同理可推导,主要是理解激活函数对数据分布的影响,后面有时间再补充吧。
5. 总结
从数理统计角度出发去分析神经网络并不是一件轻松的事情,需要加上一些强假设才能够分析下去,而且这些假设往往与实际情况有出入,例如在推导Xaiver初始化方式时,前向我们假设 i.i.d,这几乎是不可能的,因为 可能是上一个FC的结果,也就是同一个输入经过不同神经元的结果,必然会引入相关性;又如在多次迭代后, 的分布也必然发生变化,只能说影响较小。但是这个方法work了,accuracy也上去了,DL大法真是好!